
EN
在企業數字化轉型的深水區,智能文檔審核已成為提升業務效率(如財務報銷、信貸審批、供應鏈結算等)的核心環節。
然而,面對海量的業務單據、合同與憑證,許多團隊在推進文檔解析項目時發現,真正的痛點是在于“識別后如何流轉與校驗”。
傳統的 OCR 技術大多局限于單點識別。由于前端資料進來時常常是多格式混雜的,系統無法進行有效的分類與前置處理;提取出的散亂字段也往往無法直接映射到業務審核規則中。這就導致后續的資料分揀、分類、校驗和復核,只能繼續依賴大量的人工補位。識別準確率再高,審核的綜合成本卻依然居高不下。要讓文檔解析系統真正在業務中落地并轉化為生產力,關鍵不能只停留在單點識別,而是要將資料入口、字段抽取、規則配置和結果回看連成一條完整的審核流水線。
易道博識智能文檔處理工作流(DocFlux),正是基于這一全鏈路框架構建的最佳實踐。
如果前端資料仍然要靠人工分類,整體的審核效率依然很低。
易道博識DocFlux支持 PNG、JPG、JPEG、BMP、TIFF、PDF、XLS、XLSX、DOC、DOCX、PPT、PPTX、WPS 等海量格式,并支持 200M 大文件上傳。更重要的是,它可以自動識別文檔類型并進行智能分類,大幅減少人工預分揀的工作量。
以財務報銷場景為例,當員工將混雜在一起的增值稅發票、火車票、打車票甚至酒店水單一次性打包上傳時,系統能夠自動將它們精準識別并分流至對應的票種通道,大幅減少人工預分揀的工作量。
面對復雜的審核場景,易道博識DocFlux采用了“大小模型協同”的先進架構。大模型擅長處理非標長尾文檔的泛化抽取,小模型則負責高頻標準證件識別。
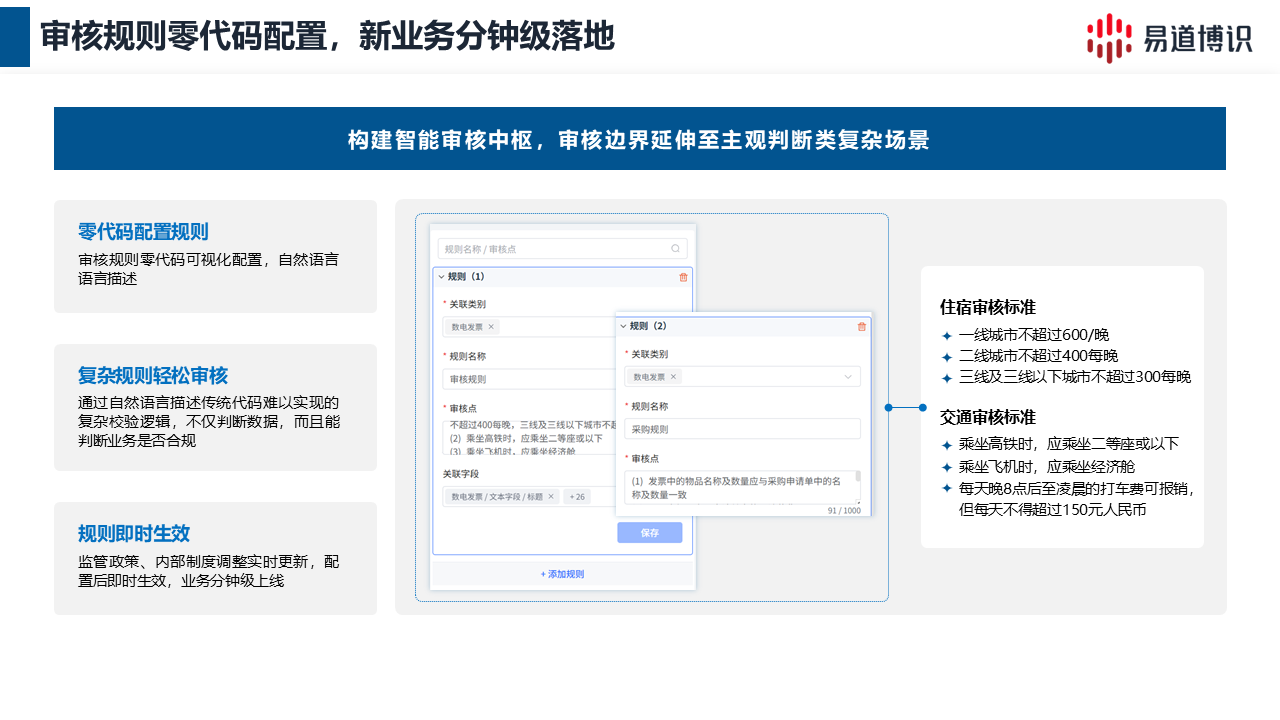
不少審核項目上線后,受限于審核規則的調整響應太慢,無法跟上業務的變化。 易道博識DocFlux支持可視化、零代碼的規則配置,甚至支持用自然語言直接描述復雜的校驗邏輯。對于規則頻繁調整的審核場景來說,這意味著業務人員可以隨時貼近業務動作調整規則,讓規則變化不再成為上線的障礙。
落地之后,復核崗位最怕的是系統給出了審核結論,卻說不清問題出在哪個字段、源自哪份原始單據。DocFlux支持直觀的結果看板,并在原始單據中高亮標記出問題字段,讓所有的審核結論都能精準溯源到源數據,滿足審計要求。
因為識別率只回答“字有沒有讀出來”,沒有回答資料能否自動分類、字段能否進入審核動作、規則變化能否快速響應,以及結果能否回溯到原始單據。落地失敗通常斷在這些環節,而不是斷在單次識別。
資料來源復雜、格式混雜、規則經常調整、審核崗位需要頻繁補錄或返工的場景更適合優先推進,比如發票、合同、銀行回單等復雜非標單據處理場景。
需要。系統更適合承擔分類、抽取、規則執行和問題定位,人工復核仍然負責業務判斷和邊界確認。好的落地方式不是取消人工,而是把人工從重復搬運資料,轉到更有價值的復核動作上。





