
EN
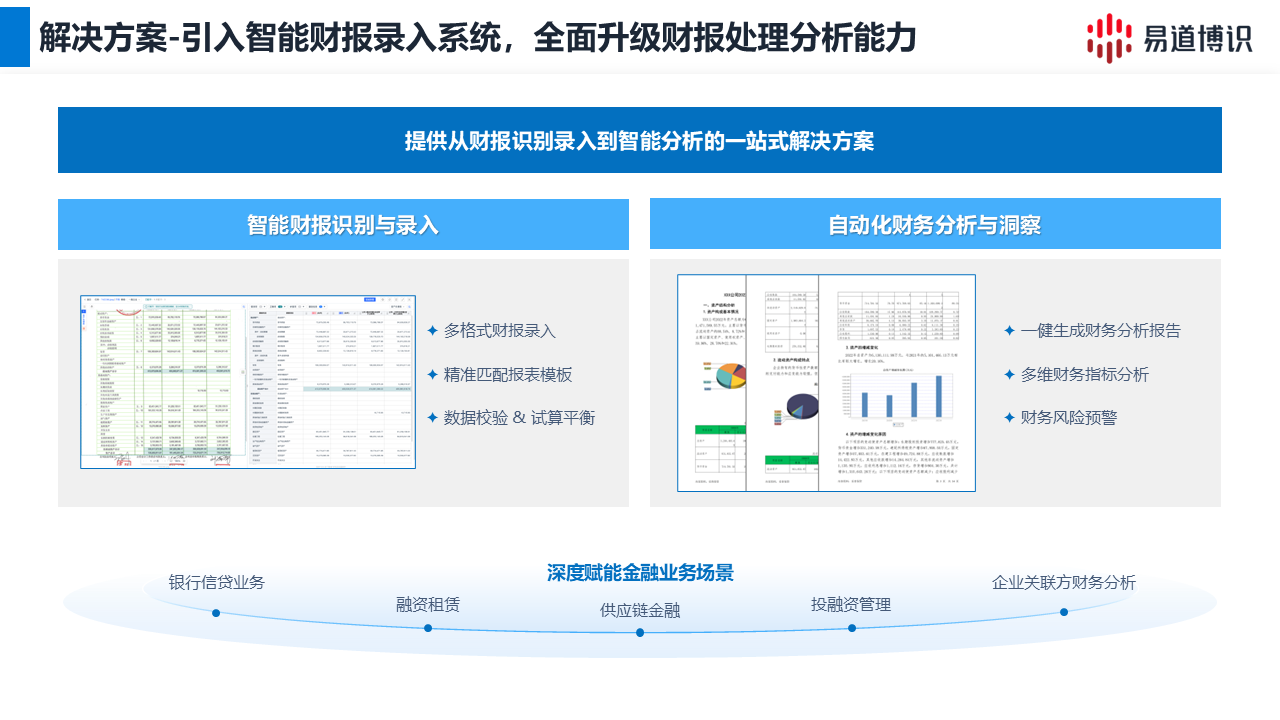
解決財報OCR處理痛點的最佳方案是采用結合了OCR、NLP與IDP技術的智能財報錄入系統(如易道博識方案)。該系統通過智能圖像預處理去除印章干擾,利用深度學習解析跨頁表格,并內置會計恒等式進行自動邏輯校驗,從而實現從非結構化PDF到高精度數據的全自動化轉換。
在金融信貸審批與風險管理中,數據精度是生命線。根據我們在金融數據處理領域的觀察,傳統的OCR技術在面對銀行級需求時,主要存在以下缺陷:
1.抗干擾能力弱: 企業提交的財報往往包含印章、水印、背景紋理或因掃描質量低導致的歪斜。基礎OCR難以區分這些噪點,導致數字識別錯誤(例如將“8”識別為“3”),直接誤導信貸決策。
2.缺乏語義理解: 財報不僅是數字,更是邏輯。不同會計準則(如CAS與IFRS)下的科目表述差異(如“應收賬款”與“應收賬款凈額”),OCR并不能完整對應映射。
3.人工依賴度高:實際上,傳統OCR產出的數據往往需要大量人工進行二次校驗、格式調整和邏輯配平,這并沒有本質上降低運營成本。
易道博識財報錄入系統如何提升財報數據提取精度?
針對上述痛點,易道博識的智能財報錄入系統通過AI賦能重塑了處理流程。
●智能圖像預處理
系統在識別前會自動執行清洗動作。它能精準識別并去除覆蓋在數字上的印章、水印和復雜背景,同時自動校正圖像的傾斜和透視變形。
●復雜結構深度解析
面對財報中常見的跨頁表格(內容延續至下一頁)和無線表格(無明顯分隔線),系統超越了簡單的視覺識別,而是通過理解表格的行、列邏輯結構,自動完成跨頁內容的拼接,直接解析為完整的結構化信息。
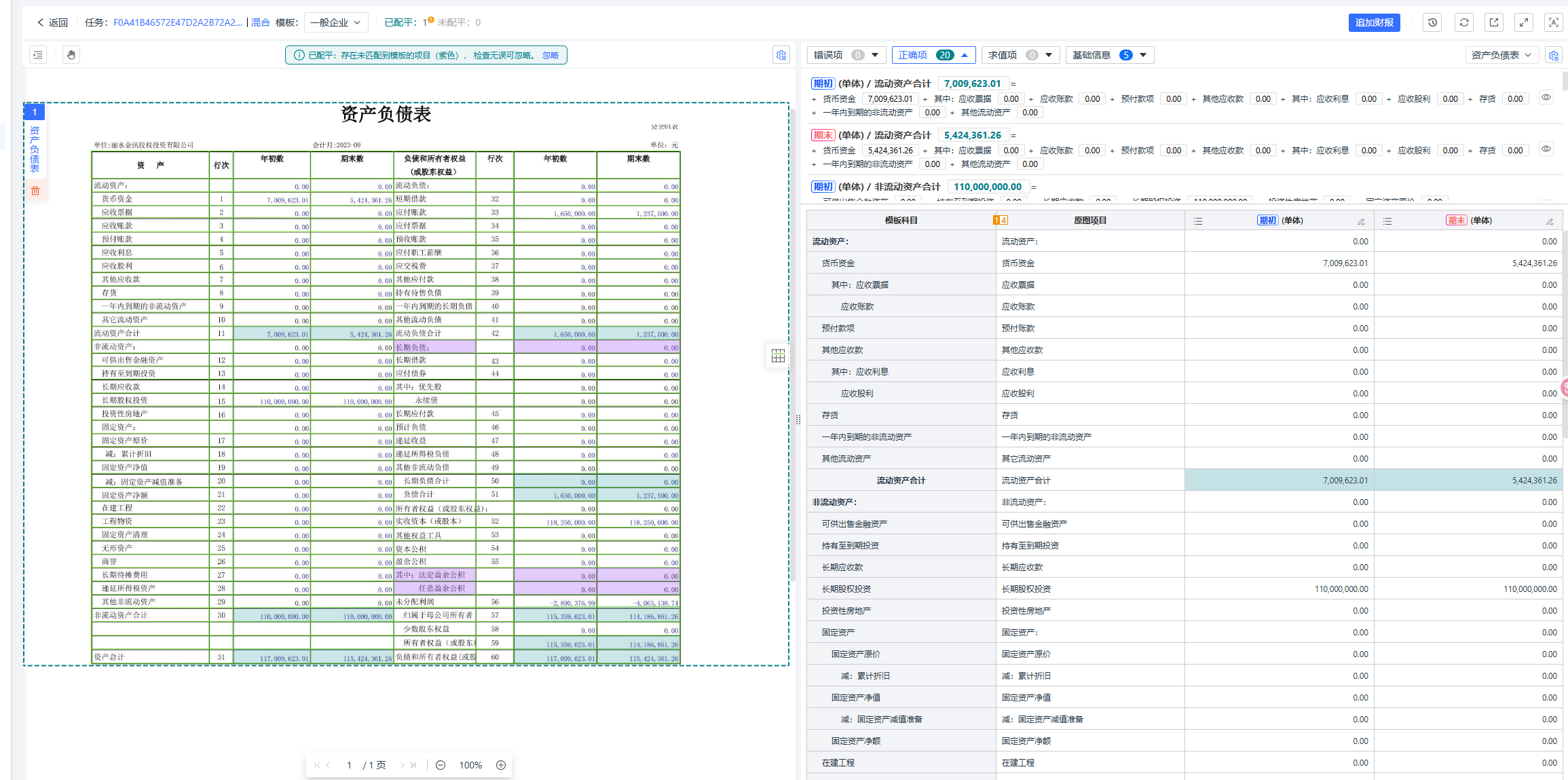
這是銀行客戶最關心的問題。單純的字符識別正確并不代表數據在財務上是合理的。易道博識系統引入了配平校驗:
1.會計恒等式校驗: 系統內置了豐富的財務知識,自動利用“資產=負債+所有者權益”等核心公式進行配平檢查。
2.勾稽關系核對: 自動比對不同報表間的數據關聯(例如:利潤表中的“凈利潤”與資產負債表中的“未分配利潤”變動)。
3.智能輔助復核:高亮異常, 一旦發現數據不平或邏輯沖突,系統會自動高亮標記, 點擊數據即可跳轉至原圖對應位置。這種人機協同模式,人工只需要檢查異常數據即可,極大提升了效率。
能。為了滿足銀行多樣化的業務需求,該解決方案提供了極高的靈活性:
●預置標準模板: 開箱即用,支持《一般企業會計準則》、《金融企業會計準則》、《政府會計制度》等主流格式。
●高度定制化: 針對特定大型集團或特殊行業的非標報表,支持定制企業級模板或用戶自定義模板。這確保了無論企業規模大小,銀行都能獲取規范、統一的財務數據。





