
EN

對于金融、審計(jì)等行業(yè)的專業(yè)人士來說,處理財(cái)報(bào)表格是一項(xiàng)基礎(chǔ)但耗時(shí)的工作。而財(cái)報(bào)OCR系統(tǒng)的核心價(jià)值,就是解決那些最棘手的表格識別問題。
對于金融與審計(jì)行業(yè)的從業(yè)者而言,財(cái)報(bào)數(shù)據(jù)提取是一項(xiàng)高頻且對精度要求極嚴(yán)的作業(yè)。專用財(cái)報(bào)OCR系統(tǒng)的核心價(jià)值,在于解決通用方案無法處理的表格結(jié)構(gòu)化難題,從而實(shí)現(xiàn)從非結(jié)構(gòu)化文檔到結(jié)構(gòu)化數(shù)據(jù)的高效轉(zhuǎn)換。
通用光學(xué)字符識別(OCR)技術(shù)的底層邏輯是“文本序列化”,即單純地將圖像像素映射為可編輯的線性文本。
這種技術(shù)路徑在處理財(cái)報(bào)時(shí)存在本質(zhì)缺陷。雖然通用引擎能準(zhǔn)確識別出“1,000”這一數(shù)值字符,但它缺乏語義理解能力,無法判定該數(shù)值是隸屬于“流動資產(chǎn)”下的“貨幣資金”,還是歸屬于“負(fù)債”科目下的“短期借款”。面對財(cái)報(bào)中普遍存在的多欄布局、跨頁表格、多層嵌套表頭以及缺乏邊框線的“無線表格”,僅憑字符識別會導(dǎo)致數(shù)據(jù)邏輯斷裂,輸出結(jié)果往往是雜亂無序的文本堆砌。
表格復(fù)原的難點(diǎn)不在于字符本身的識別精度,而在于對表格“邏輯拓?fù)浣Y(jié)構(gòu)”的重建。
先進(jìn)的財(cái)報(bào)識別系統(tǒng)摒棄了單一的文本識別模式,轉(zhuǎn)而采用多階段的智能處理流。該流程通過深度學(xué)習(xí)模型,系統(tǒng)性地解決從版面定位到邏輯重組的技術(shù)挑戰(zhàn)。
系統(tǒng)首先對文檔進(jìn)行全局視覺掃描。算法將自動區(qū)分文檔中的不同版面元素,精確框選表格區(qū)域,同時(shí)剝離正文敘述、頁眉頁腳及頁碼等非表格干擾項(xiàng)。這一步驟確保了后續(xù)計(jì)算資源能夠集中于核心數(shù)據(jù)區(qū)域,為高精度的結(jié)構(gòu)化處理確立邊界。
系統(tǒng)利用計(jì)算機(jī)視覺技術(shù)檢測顯性與隱性的表格分割線,定位所有文本塊的物理坐標(biāo),并解析其行列屬性。在此過程中,模型會構(gòu)建一個(gè)包含行索引與列索引的邏輯骨架,確立“父級表頭”與“子項(xiàng)數(shù)據(jù)”之間的多維映射關(guān)系。例如,系統(tǒng)將在此階段鎖定“資產(chǎn)”作為頂級維度,并建立其與下轄“貨幣資金”等子科目的層級關(guān)聯(lián)。
在穩(wěn)固的結(jié)構(gòu)框架建立之后,系統(tǒng)啟動OCR引擎進(jìn)行字符提取。
基于已解析的行列坐標(biāo),OCR引擎針對性地識別每個(gè)單元格內(nèi)的具體數(shù)值與文本。這種“先結(jié)構(gòu),后內(nèi)容”的處理次序至關(guān)重要:若缺乏準(zhǔn)確的邏輯框架,即便是100%的字符識別率也無法生成可被機(jī)器理解的數(shù)據(jù)。只有當(dāng)結(jié)構(gòu)解析無誤時(shí),識別出的數(shù)字才能轉(zhuǎn)化為具有業(yè)務(wù)價(jià)值的財(cái)務(wù)信息。
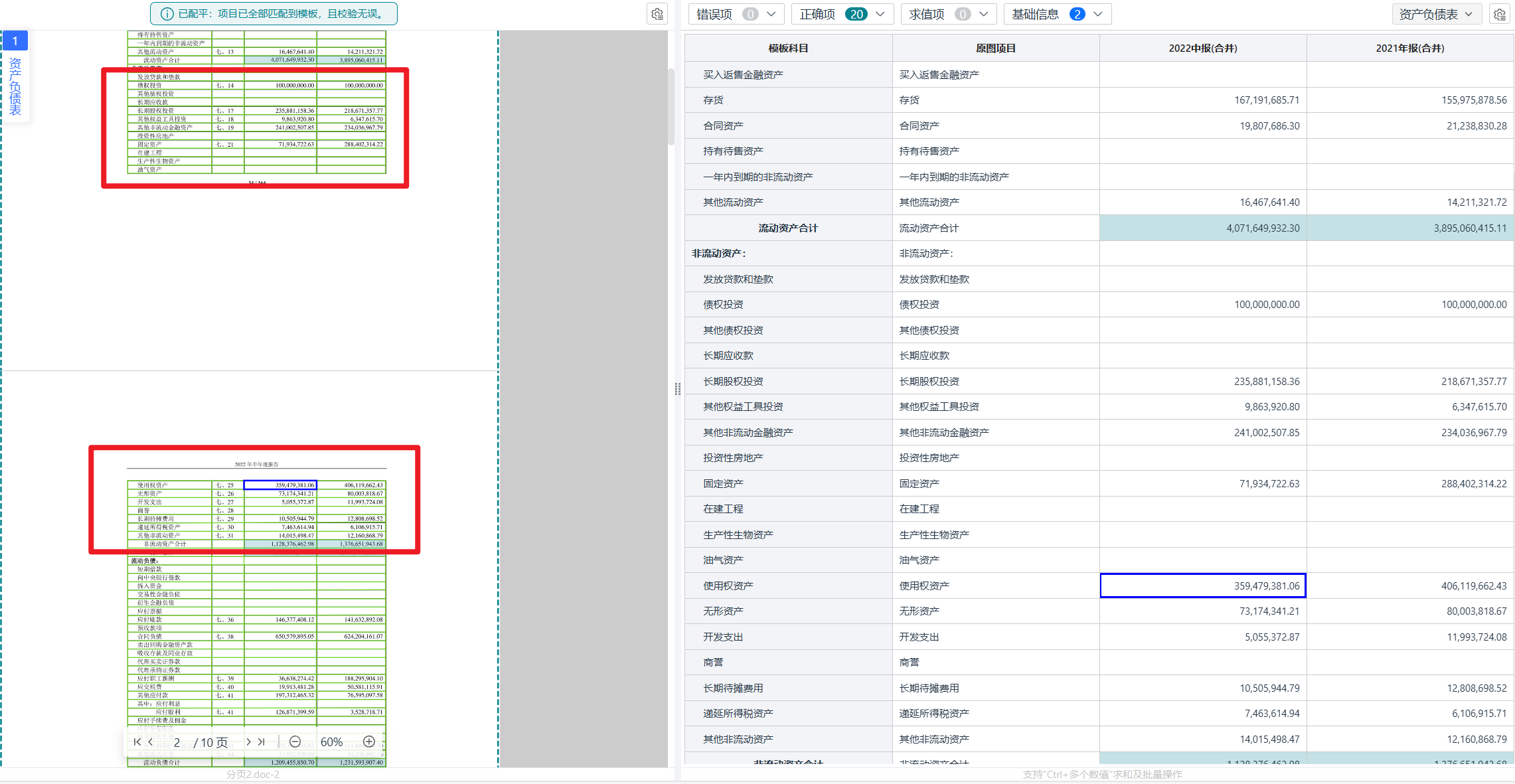
“跨頁斷裂”是處理財(cái)報(bào)表格時(shí)最讓人頭疼的問題之一。一個(gè)完整的財(cái)務(wù)報(bào)表,可能從第10頁開始,到第11頁才結(jié)束。
●傳統(tǒng)OCR的失敗點(diǎn): 許多系統(tǒng)在處理跨頁表格時(shí)會“失憶”。它們在第11頁時(shí),已經(jīng)忘記了第10頁的表頭是什么,導(dǎo)致第11頁的數(shù)據(jù)全部丟失或錯(cuò)配。
●易道博識智能財(cái)報(bào)OCR的解決方案是,在第一步“版面分析”時(shí),就會檢測到“跨頁”的信號。它會通過表格拼接,主動尋找第10頁的“斷裂處”和第11頁的“接續(xù)處”,先將它們拼接成一個(gè)完整的表格。拼接完成后,系統(tǒng)會應(yīng)用表頭語義繼承”邏輯,將第10頁的表頭(如“項(xiàng)目”、“本期金額”、“上期金額”)自動應(yīng)用到第11頁的數(shù)據(jù)行上。這樣,無論表格有多長、斷裂了多少次,系統(tǒng)都能確保每一行數(shù)據(jù)都與正確的表頭機(jī)關(guān)聯(lián)。
問題:財(cái)報(bào)OCR的識別準(zhǔn)確率能達(dá)到多少?
回答: 這是一個(gè)雙重指標(biāo)。對于數(shù)字和文字的OCR識別率,目前主流技術(shù)(如易道博識)可以達(dá)到99.9%以上。財(cái)報(bào)一次配平率超95%。
問題:財(cái)報(bào)OCR識別錄入系統(tǒng)與現(xiàn)有業(yè)務(wù)系統(tǒng)集成難度大嗎?
回答:系統(tǒng)提供標(biāo)準(zhǔn)API接口和多種數(shù)據(jù)輸出格式(如Excel, JSON),與常見的信貸、風(fēng)控系統(tǒng)集成經(jīng)驗(yàn)成熟,技術(shù)難度可控,實(shí)施周期明確。




