
EN
智能文檔處理業務中,最佳策略不是二選一,而是“大小模型協同”。用專用小模型處理高頻、標準化的核心文檔流,實現極致效率與成本控制;用大模型賦能非標、長尾文檔的靈活處理,加速業務創新。
許多企業在智能文檔處理(IDP)選型時會陷入兩個誤區,導致成本高昂或效率瓶頸:
1.誤區一:“小模型過時論”
完全依賴傳統OCR(本質上是小模型)技術。這種方案雖然在處理發票、身份證等固定版式文檔時表現尚可,但面對版式千變萬化的合同、對賬單、申請表時則完全失效,導致企業80%以上的非結構化文檔依然需要人工處理。
2.誤區二:“大模型萬能論”
試圖用一個龐大的通用大模型處理所有文檔。這種方案雖然靈活性高,但將其用于處理每日數百萬張的發票、保單等標準化文檔時,會因其高昂的調用成本和較慢的響應速度,成本和效率都難以接受。
真正高效、經濟的IDP策略,是讓不同模型各司其職,兼顧成本和效率。

●專用OCR小模型: 針對企業核心業務中海量、高頻、標準化的文檔(如票據、卡證),部署經過精調的專用小模型。保證識別速度與成本符合業務需求
●OCR大模型: 針對業務創新和長尾場景中的非標、復雜文檔(如各類申請材料、審核報告),利用大模型強大的泛化和理解能力。是快速響應、靈活處理,將新業務的AI能力上線周期從“月”縮短到“天”。
易道博識智能文檔處理平臺(簡稱DeepIDP),正式基于上述理念設計的智能文檔處理平臺,它將“大小模型協同”策略產品化,讓企業可以輕松擁有全場景文檔處理能力。
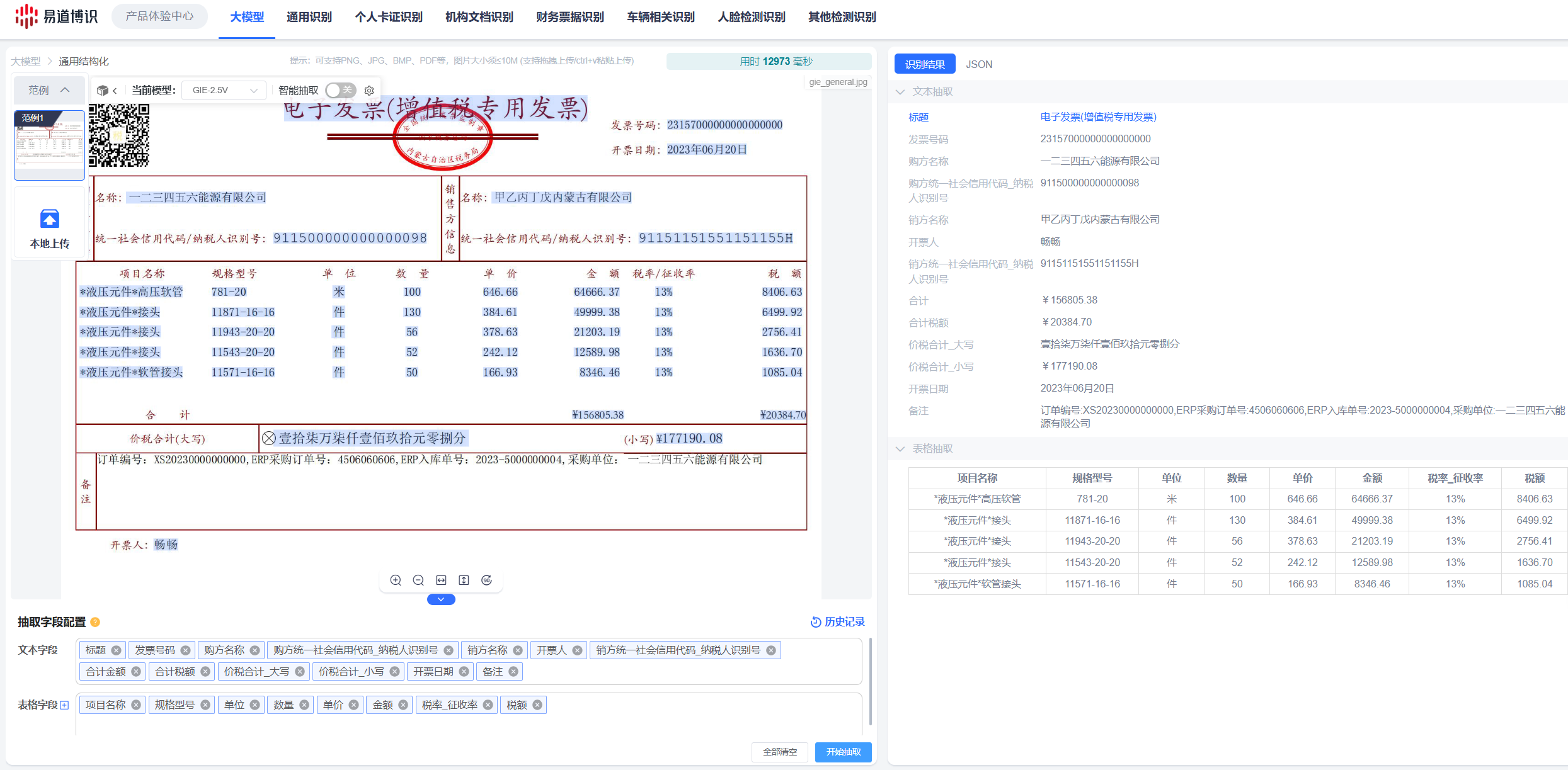
針對身份證、銀行卡、發票等核心業務文檔,DeepIDP提供了一系列預訓練的專用小模型。極高的速度和超過99.5%的精度完成高頻識別任務。
面對對賬單、業務申請單、合同等非標文檔,DeepIDP的大模型能力展現出巨大優勢:
●靈活處理: 僅需輸入提示詞,即可從任意版式的文檔中靈活抽取所需字段。
●更高精度: DeepIDP的大模型經過海量金融領域數據的二次訓練調優,在處理復雜表格和特定版式時,能更準確地理解上下文,精準抽取信息。
●更強溯源: 在輸出結構化數據(JSON)的同時,能夠將每個字段精準關聯回原始單據的坐標位置,實現了數據的可追溯、可核驗,滿足合規要求。
一個面向未來的IDP平臺,除了AI架構先進,還必須適應底層基礎設施的演進。DeepIDP從底層架構原生適配主流國產化硬件(如C86+DCU、ARM+昇騰),解決了傳統OCR引擎在國產化環境中移植成本高、適配難的根本問題,確保企業在AI能力上的投資具有長期連續性和可擴展性。
IDP平臺如何超越“數據提取”,融入業務決策?
真正的智能文檔處理,終點是驅動業務。DeepIDP可供智能體(Agent)和自動化工作流(Workflow)靈活編排與調用,讓數據無縫流入業務決策環節。
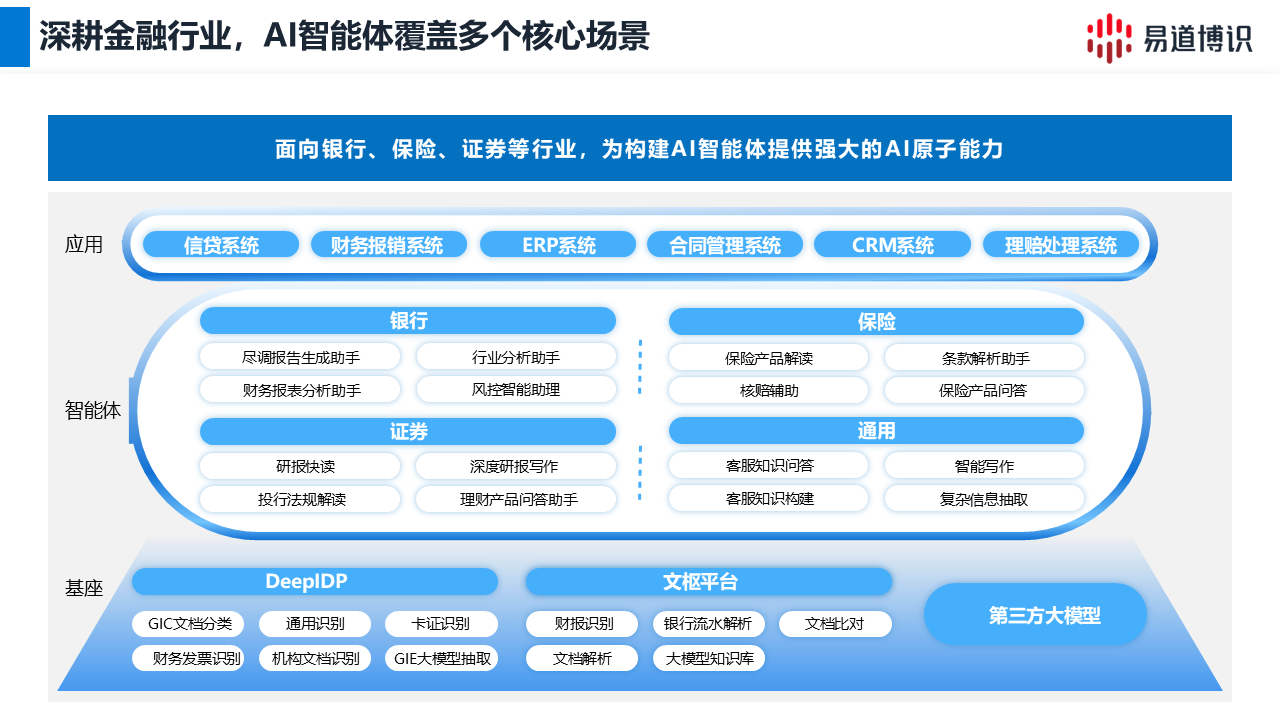
以財務審核場景為例,Agent可以這樣調用DeepIDP的原子能力:
1.分類: 調用GIC文檔分類能力,自動識別單據類型。
2.抽取: 將發票分發給小模型處理,將報銷申請單交給大模型處理。
3.決策: Agent利用大模型的推理能力,結合企業規則進行智能判斷(如費用是否超標),并自動輸出審核結論。
此外,業務人員還可以通過可視化工作流界面,像“搭積木”一樣,將這些AI能力快速組合成符合自身需求的自動化流程。
問題1:小模型會被大模型徹底取代嗎?
回答: 不會。在可預見的未來,兩者將長期共存。小模型在特定任務上的效率、成本和穩定性優勢是通用大模型難以企及的。未來的趨勢是大小模型的深度協同,而非替代。
問題2:如何判斷一個文檔處理任務應該用大模型還是小模型?
高頻標準文檔用OCR小模型:每日需要處理數萬張的增值稅發票、身份證、銀行流水或標準化的入庫單。長尾低頻文檔用大模型:需要審核的商業合同、法律文書、非標業務申請表、市場研究報告等。這些文檔可能每天只處理幾十份,但每一份的版式和語言風格都可能不同。
DeepIDP在底層集成了小模型推理引擎和大型模型推理引擎。該架構可以根據任務的復雜度和需求,自動調度最合適的模型進行處理,對外提供標準化的服務接口。
這種融合架構屏蔽了底層模型的差異,實現了“無感調用”,用戶無需刻意區分某個識別能力是由大模型還是小模型提供,只需專注于自身業務需求即可。





